This is the third part of blockchain design 101 series. You can read second part here. In this part we are going to present an overview of ethereum and cosmos hub.
Cosmos Hub connecting to Ethereum network via Peg Zone using IBC protocol
Ethereum Muir Glacier
Ethereum is the second largest Proof-of-Work network behind bitcoin. It’s defining innovation over previous proof-of-work networks is introduction of EVM (Ethereum virtual machine) which runs on every ethereum node deterministically. Combining EVM with proof of work consensus, ethereum network as a whole act as a “World Computer”, where any deterministic immutable computer program compilable to byte code interpretable by EVM can run. Programs can also interact with each other via calling any entrypoint of other programs. Since ethereum byte code is Turing complete, ethereum can run any complex program given enough execution fees. To make state transition operation successful, users need to pay some amount of execution fee in proportion to the complexity of the operation.
Users can submit three types of state transition operations (or in ethereum terminology a transaction) to network:
Send some Ether to one account to another account or program
Call any entrypoint of a program with zero or more parameters
Deploy a new program
Ethereum’s native currency is called Ether and the smallest fraction of Ether is called Wei. One Ether equals to 1019 Wei.
Block construction
In ethereum, Ethash algorithm is used as a proof of work computational puzzle. Ethash uses a large dataset that is periodically regenerated and slowly grows over time, which makes it fairly ASIC resistant. To mine a block, node needs to find an eight-byte nonce which satisfies Ethash’s verification conditions, which can be tuned to increase/decrease difficulty. Ethereum tries to keep time required to solve the puzzle in a range of 10 to 19 seconds regardless of continuos change in total resources of the network by adjusting difficulty depending upon time taken to solve the puzzle for the previous block. Once node finds a solution to the Ethash puzzle, it will prepare a block and broadcast it into the network.
Block contains a set of state transition operations and block header containing nonce, reference to parent block, and optionally reference to siblings of its parent.
Whenever a node constructs a valid block and it becomes part of the canonical fork, node is rewarded:
Fixed fee of 2 Ether as a reward for constructing a valid block
Execution Fee (Or in ethereum terminology Gas) for every state transition operations included in the block
Fork selection
Ethereum node selects a fork that has maximum Ethash difficulty calculated as a sum of difficulties of all blocks contained. Since Ethash difficulty is dynamically adjusted, it is not always a case that the longest fork is the one with the most difficulties.
Block Finality
Ethereum offers probabilistic finality as we discussed in the previous part. For almost all use-cases, if seven new blocks are built upon the target block, it is enough to consider that block final.
Cosmos Hub v2.0
Cosmos Hub is one of the famous proof of stake network and is called an “Internet of Blockchain”. Its strength lies in facilitating interoperability between fully sovereign blockchain by acting as a hub using a protocol called IBC. For now, only the top 100 candidates with most stake can become a validator.
Users can interact with cosmos hub by sending a state transition operation, which will be routed internally to a specific module that handles that operation.
Cosmos Hub’s native currency is called Atom.
Block construction
Since cosmos hub is proof of stake blockchain, every validator which has stake in form of ATOM is eligible to produce a block. Every consensus round, a validator is chosen as a block proposer based on a weighted round-robin algorithm, where weight is in proportion to that validator’s stake. If either proposer is offline or due to any other reason isn’t able to broadcast the block in stipulated time, next validator as per round-robin algorithm is chosen as proposer.
Block contains a set of state transition operations (or in cosmos terminology a transaction) and block header containing reference to parent block and optionally future change to current set of validators.
Staking
Cosmos Hub requires validator to stake some amount of ATOM as collateral and in return, validator gains the chance to be elected as a proposer as well as have voting power in proportion to ATOM staked. In addition to this, it supports delegated proof of stake which allows users who can not or do not want to run the validator to delegate their funds to one or more validators of their choice and will be compensated with some portion of the revenue of those validators. These users are called delegators.
Validators and delegators earn rewards in two ways:
Atom Inflation: New atoms are created every block and distributed to validators and delegators participating in the consensus process. This mechanism exists to incentivize Atom holders to stake them, as non-staked atom will be diluted over time.
Execution fees: Every state transition operation submitted to cosmos hub need to include some amount of fee in proportion to complexity of the execution.
Above mentioned rewards are first distributed to individual validators in proportion to their stake in the network. Then for every validator, rewards will be further distributed among delegators of said validators in proportion to their contribution in the validator’s total stake.
Fork Selection
In cosmos hub, only one validator can propose block at a given height and until that proposed block is either finalized or rejected network cannot make further progress. Due to this, there cannot be any fork as long as less than 1/3rd of nodes are faulty.
Block Finality
To finalize a block, validators with a combined voting power of >66% need to vote for that block. Once a block is finalized, it cannot be reverted unless majority of validators in the blockchain agree to roll back their local states.
This is final part of the Blockchain Design 101 series. In the next series, we will look at advanced blockchain design concepts.
This is the second part of blockchain design 101 series. You can read first part here. In this part, we are going to talk about two of the most popular blockchain designs.
Proof-of-Work
Proof of work blockchain gets its name from the fact that node requires to do some work, in order to produce a block.
Block construction
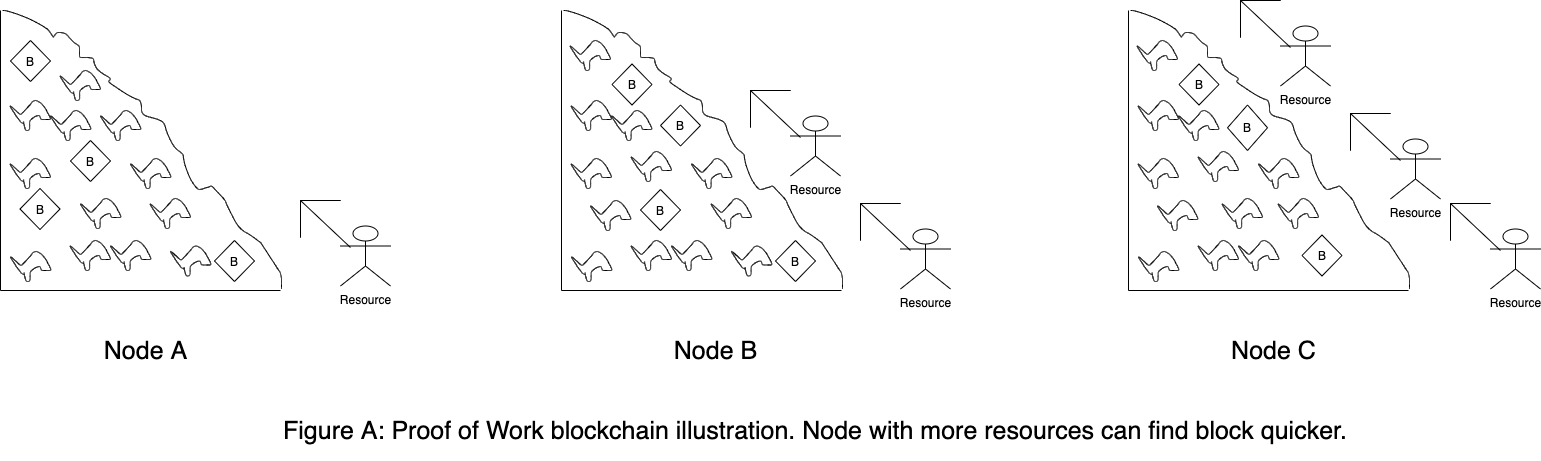
In Proof of Work blockchain, To construct a valid block node need to find an answer to a computational puzzle. This puzzle needs to be such that finding an answer requires a node to put significant but finite and quantifiable effort in terms of resource usage (for example memory, CPU, or network), but verifying correctness of that answer need to be quick and easy. Effort required to calculate the solution can be quantified in terms of amount of resources utilized and can be expressed in units of difficulty. Every node competes in finding a solution and producing a block as quickly as possible. So, a node with more resources has more probability of producing a block in lesser time and consequently more probability of including it in the blockchain.
Fork selection
A fork with most difficulty as sum of difficulties of all blocks contained can be seen as a fork chosen to extend by a set of nodes with the largest cumulative resources. So, a node is incentivized to select that fork to append new block, due to high probability of said block remaining canonical. Since, significant amount of effort is required to produce a block, nodes are discouraged to extend multiple forks concurrently.
Block finality
Pure proof of work blockchain offers probabilistic finality. There is always some probability however small, that block can become non-canonical once another fork at less height overtakes that block’s fork by increasing its own difficulty quicker. Probability of that happening is inversely proportion to amount of difficulty added on top of said block, as more difficulties added on top less chance for a fork created at height less than block to overtake said block’s fork.
Caveats
In proof of work blockchain every node need to do some effort while competing to produce the block, which is very costly in terms of energy usage. Since solving computational puzzle takes some time, block generation in Proof of work is slow by design.
Proof-of-Stake
Proof of stake differs with Proof of work by shifting the requirement of block production for node to holding a stake in blockchain as opposed to finding a solution to puzzle. This speeds up block generation considerably.
Block construction
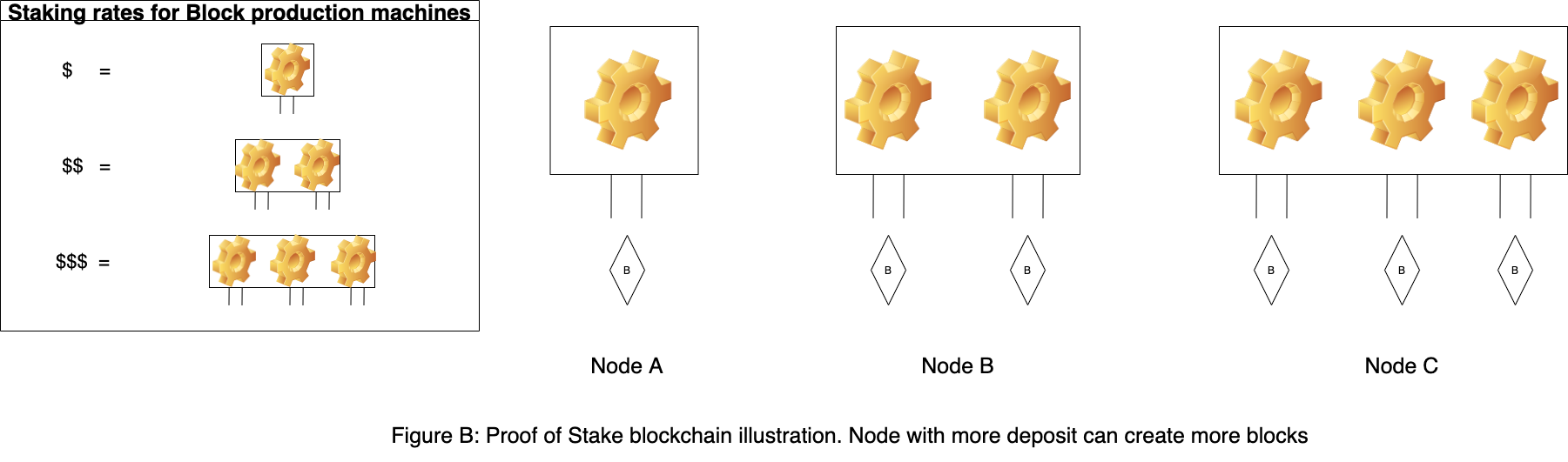
In proof of stake blockchain nodes that have locked up some stake in blockchain can only produce block and make an assertion. More stake node has more probability of it to produce the block and more weight to its assertions. In most implementations to make sure nodes act honestly, every node is required to put some portion of its stake as collateral which can be slashed if misbehavior proof is found. Validating a block require nodes with combined majority stake to assert that said block is valid.
Block finality
Proof of stake blockchain offers either absolute finality or probabilistic finality. Probabilistic finality works same as Proof-of-Work blockchain.
In case of absolute finality support, Some of the most common strategies employed by different implementations are as follows:
Before finalizing previous block, next block cannot be constructed. In this case forks are not allowed, as it is not possible for any siblings of a block to exist.
A distributed algorithm finalizing blocks depending upon certain parameters like block age, combined stake of nodes which asserted validity of that block, number of blocks built upon that block etc.
A distributed algorithm finalizing a block depending upon finality assertions made by nodes for that block or its descendants.
Fork selection
Fork selection in Proof of stake system is completely implementation dependent. Protocol level mechanism is required to discourage nodes to extend multiple forks.
Caveats
Since in proof of stake blockchain there isn’t any physical anchoring of blockchain as opposed to proof of work where you have to spend real world energy to produce blocks, some protocol level attacks are comparatively easy to carry out in the naive implementations.
In the next part, we will do a case study of the most popular implementations of Proof of Work and Proof of Stake design.
This is the first part of blockchain design 101 series. You can read second part here. Aim of this blog series is to describe in detail what goes under the hood of blockchain. In this part, We are going to talk about some common blockchain concepts.
What is blockchain?
Generically, Blockchain is a tree of block of data linked with each other cryptographically. What this means is every block is built on top of its parent in such a way that changing contents of the parent invalidates child block. This forms core security aspect of blockchain.
Every blockchain implementation is unique, but they share some common concepts.
State machine
State machine describes how blockchain transitions from current state to next state. It requires two inputs:
Current state
State transition operation
For correct operation of blockchain, state machine must be deterministic for every possible input. So that all correct node reaches same state, upon consuming same input.
Genesis state
Initial state from which all nodes in the blockchain start is called genesis state. It is typically determined by node operators offline.
State transition operation
State transition operation describes what operation state machine needs to perform on the blockchain state, and is interpretable by the state machine. Given current state, successful interpretation produces a changeset, which is then applied by state machine to current state to produce next state. For blockchain to function correctly, state transition operation needs to be atomic and reversible.
Two types of state transition operations exists:
User submitted: Typically submitted by user via api exposed by nodes.
System generated: Generated as part of system operation. One example would be enacting a new validator set in Proof-of-Stake blockchain.
Block
Every block except genesis block contains three things:
A cryptographic data that links a block to its parent
Zero or more state transition operations
Some portion of current state of blockchain.
Genesis block
Blockchain’s tree of block has one root block called genesis block, derived from genesis state. In most blockchain implementations, Genesis block is not allowed to contain any user submitted state transition operation, but system generated state transition operation can still be part of it.
Block construction
Defines which node has the right to construct the block, and which state transition operations can be part of that block. In case of some implementation, nodes can produce different blocks from same parent depending upon some conditions. One scenario in which this might happen where due to network partition some nodes on network does not receive the block constructed by current block constructor and are allowed to produce a different version of block for same tree height.
Block finalization
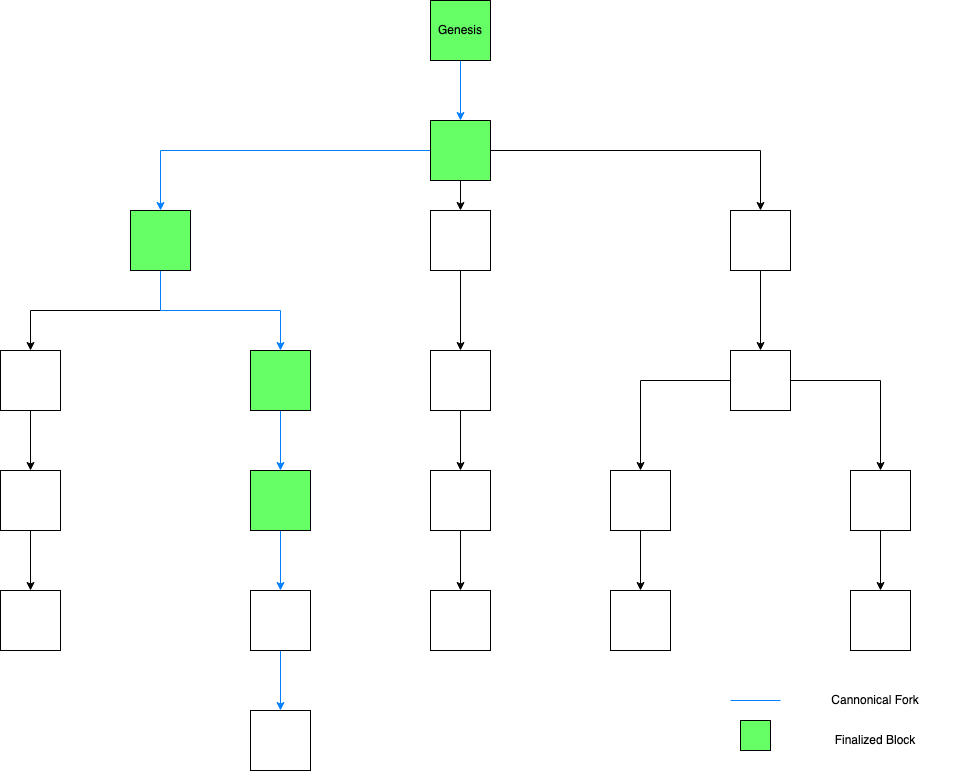
Refers to how nodes in blockchain determine which block to finalize out of all siblings at a particular height of tree. When we say a block is finalized, it means that out of all siblings of blocks, that particular block is considered as confirmed and depending upon actual implementation it is either impossible or only possible with significant effort to revert changeset produced by interpretation of said block.
Fork selection
Fork selection refers to how nodes select best fork for them to append new block to. Here fork is defined as a path from root node to one of the leaf nodes. In some implementations, this selection process can be greedy, where nodes select fork which maximizes their rewards. Best fork must contain all finalized blocks.
In the next part we will discuss different blockchain designs and how they evolved.
Remote procedure call (RPC) is basically a form of inter-process communication. It is widely used in distributed computing.
In this blog post, We will build a simple RPC server step by step.
1. Define an interface and shared structs
For sake of simplicity, we will choose an interface with two methods: Multiply and Divide, which perform * and / operations respectively.
There will be only two shared structs called Args and Quotient that will be used to pass arguments from client to server and represent the output of Multiply and Divide respectively.
2. Write implementation for the interface
Now, we will write struct which implements two methods we mentioned above: Multiply and Divide.
3. Implement a RPC server
Two ways we can implement a RPC server in golang:
3.1 HTTP RPC
In this case server will be listening for incoming connection using HTTP protocol, and will switch to RPC protocol afterwards.
Benefit of this approach is, you can perform authentication of client easily, before allowing RPC, using any authentication method supported by HTTP.
Internally, server listens for HTTP CONNECT method, and then uses http.Hijacker to hijack the connection.
3.2 TCP RPC
In this case server will be listening for incoming connection directly, instead of relying on HTTP protocol.
4. Implement a RPC client
We need to implement RPC client, based on which way we chose to build our server.
Starting from golang 1.1, it offers reflection support to do almost anything dynamically. Combine that with functional programming support, and you can write generic functions that operate on combination of any data type and function.
In this article, I will describe how to write generic functions in golang, as well as disadvantages of it, compared to static functions.
Functional Programming in Golang
Golang supports first class functions, higher-order functions, user-defined function types, function literals, closures, and multiple return values.
For scope of this article, I will demonstrate three of the above features: function literals, function types and higher order functions.
In this example, we implemented filter function, that takes two arguments, slice of integer and a function. And filter the slice using the function passed.
As you can see, we call filter function, two times with different function literals, first literal filters out odd numbers, while second removes even numbers.
But, this is not enough to write truly generic code, as you can see, we can only pass integer slice and only functions who are compatible with function type that we declared beforehand.
Enter reflection!!
Reflection in Golang
Unlike C/C++, in golang every object retains associated type information, even if it is assigned to a variable with interface{} type. This feature plays key part, while using reflection.
Reflection apis are exposed in golang, through built-in package called reflect.
There are two central concepts, in context of reflect package which we need to understand before diving into the code:
Type: It is an Object that represent go types as well as user defined types. For example: int, string, map, func.
Value: It is an Object, which encapsulates and act as an interface to the underlying Go Object. It is useful when we want to do some common operation on the object of particular kind (i.e array or map).
With help of reflection and functional programming, we can write a generic function in go, with run-time type safety.
By run-time type safety, I mean that the types of a function’s arguments are consistent with semantics of function or else the function predictably fails at run time with a reasonable error message.
As you can see in this example, we have used Value, and Type cleverly, to check if input parameters confirms the semantics of mapping, and to construct output argument.
Word of Caution
There are certain disadvantages of using generic functions:
They are very very slow: Generic functions are quite slow. For example map function in previous example, is almost 100x time slower than its static counterpart.
You lose on compile time error checking: As you can see, the function we have written accepts anything for its parameters, thanks to interface{} type. This makes it very flexible to use this function for different data types. But, that also mean that now the compiler, cannot point out error at compile time. Probability of writing erroneous code also increases in this case. So for large generic program, we must rely on extensive testing to make sure, it works properly.